Table of Contents
- DNS: the what and the how
- where is the amplification at?
- but how is it an attack?
- enough talk, show me the code
DNS: the what and the how
the what
The domain name system (DNS), for the lack of a better analogy, is similar to the concept of phone books. You know the name of the person you want to reach but you don’t know their phone number – so you look it up in the phone book and connect to them.
Unlike phone numbers that we humans use to communicate, computers communicate with each other via IP addresses.
When you want to visit a website – say instagram.com – your computer does not know where that is. So, your computer queries the DNS servers on the internet that it knows about to ask about the website that you want to visit. Think of these DNS servers as numerous phone books of the internet which are regularly updated. In turn, the DNS server reverts back with a (or often several) IP addresses of the website that you want to reach.
This was a tiny summary describing the task of DNS servers, you can visit Cloudflare’s fantastic blog post on it if interests you.
the how
I won’t delve into the detail as to the structure of DNS requests or the underlying UDP frames that carry these as payload other than stating that the DNS query is encapsulated by a UDP frame and is then catapulted to the realms of the internet in hope of a response from the DNS server (UDP is stateless, connectionless and unreliable).
If you are interested to read up more on the structure of DNS packets you can have a look at this fantastic article titled “UDP Socket Programming: DNS” and if you want to learn more about the structure of UDP frames, you can have a look at the Wikipedia article on UDP.
where is the amplification at?
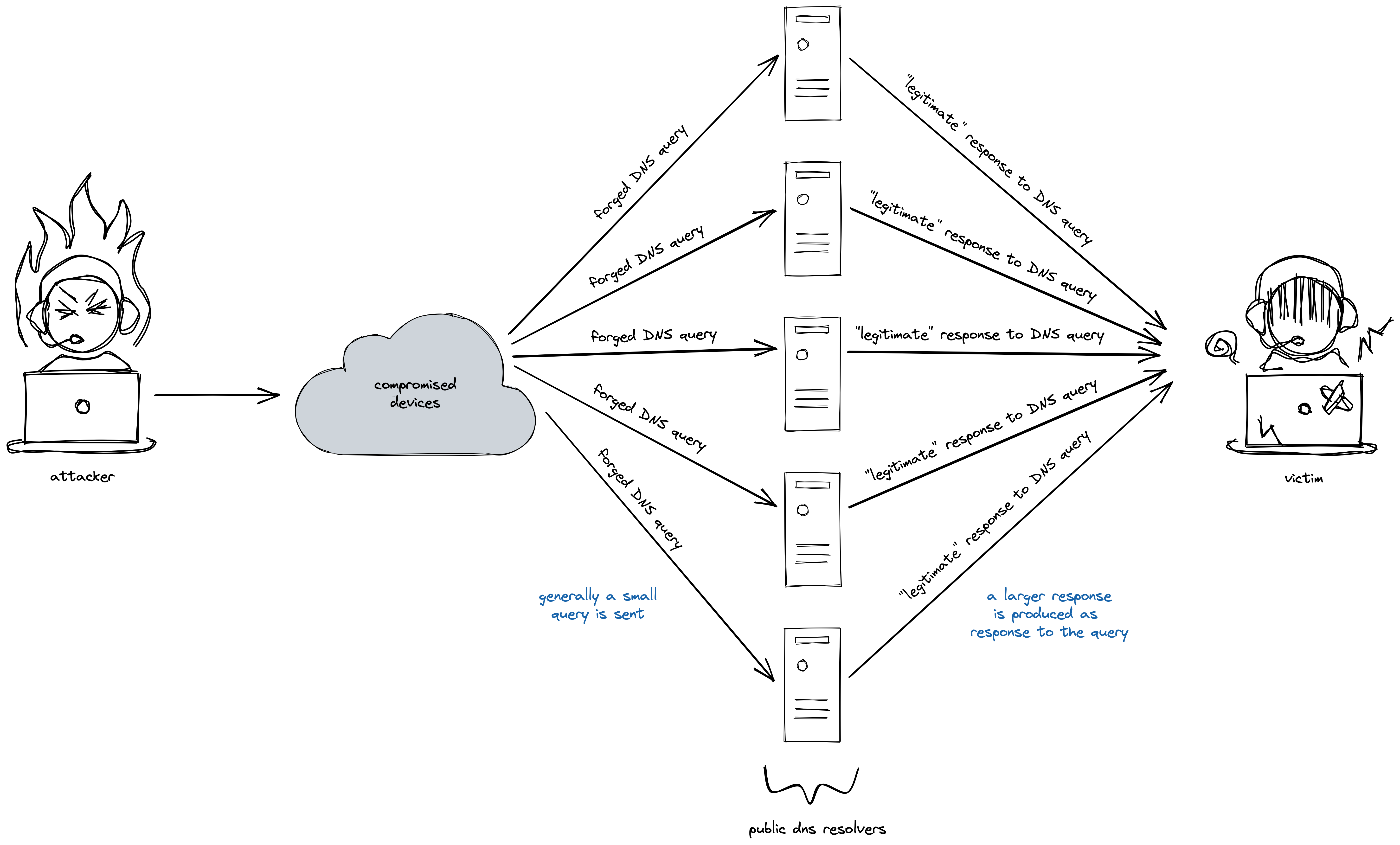
When there is a disparity between the size of the response of a query and the query itself, an attacker is able to exploit the difference and gain more damage from a lesser expense. Responses to a DNS query such as zone transfers or a query for all resource records are generally a lot larger than the query message itself.
If you run dig @1.1 ANY google.com command in your terminal and capture the resulting traffic, you will notice
something like the screenshot below.
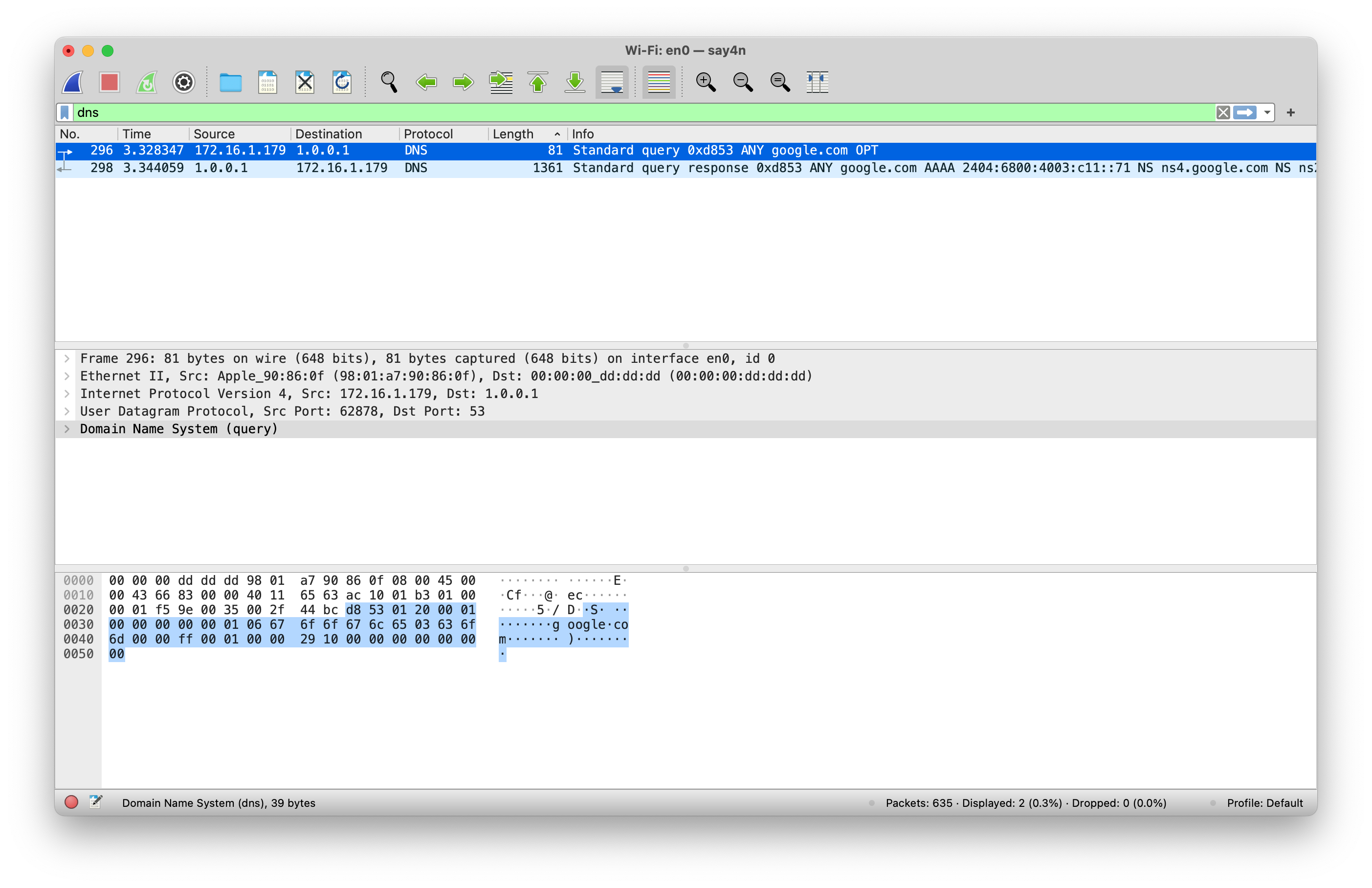
As you can observe from the screenshot, the outgoing request is a mere 81 bytes in length, whereas the incoming response is 1361 bytes in length. That is almost a 17 times request to response ratio!
but how is it an attack?
Now the keen eyed readers amongst you may have noticed the source IP address field from the screenshot of the DNS request above.
What the attacker needs to do is to craft this DNS query in such a way that the source IP address for the query is altered to be the attacker’s victim’s IP address. When this is done, the responding DNS server will mistakenly assume that the the DNS query originated from the victim and sends its response to malicious query to the victim server.
The attackers typically use large botnets to generate such spurious DNS queries and the deluge of responses from various DNS servers causes the victim to become overwhelmed by the sheer bandwidth of traffic that it is ill-prepared to handle.
The captured traffic from a DNS request with an altered source IP will look something like this.
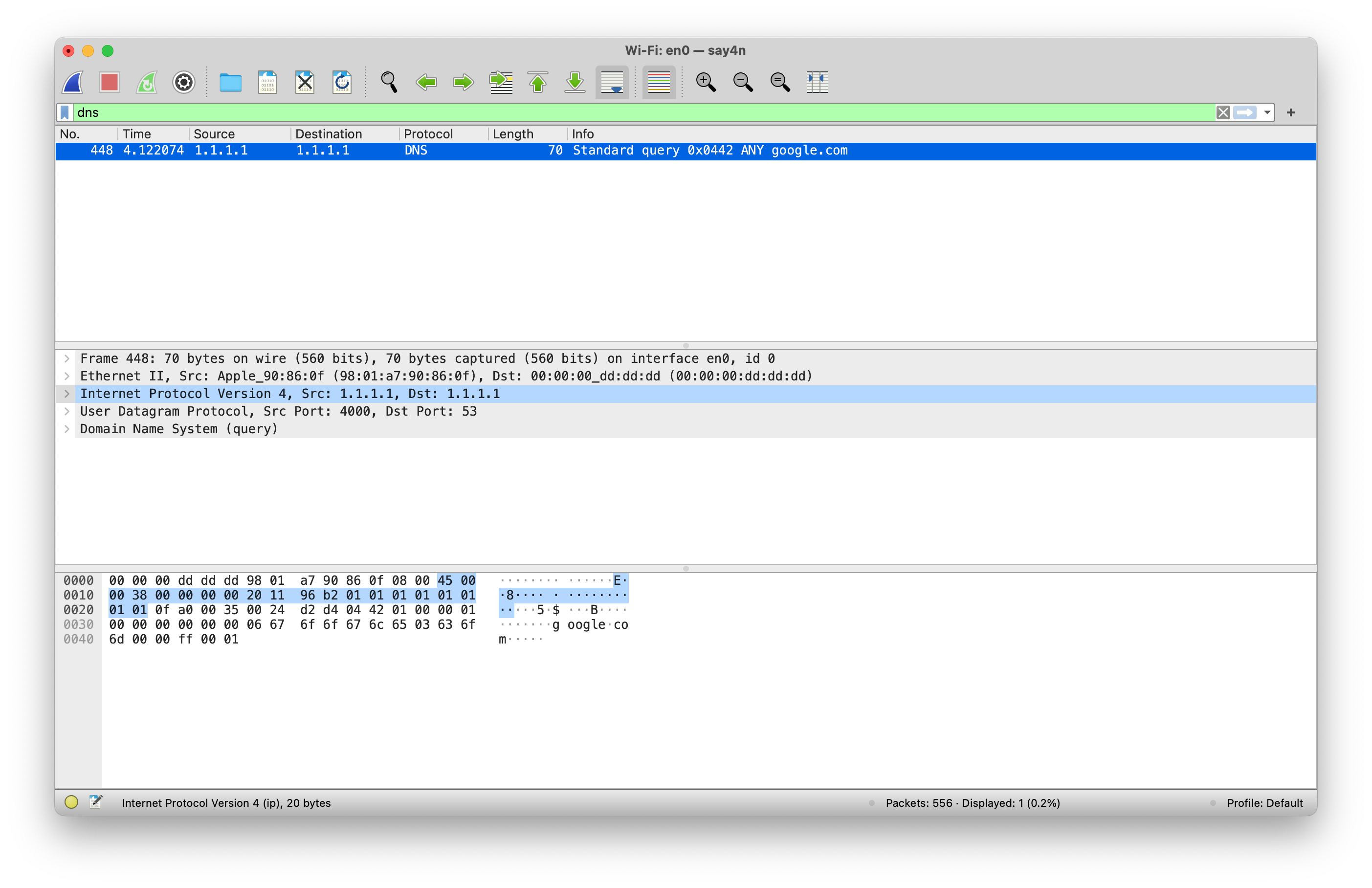
Notice the source and the destination IP address fields are the same in the picture and I can assure you that my IP address is not 1.1.1.1. When the DNS server replies (if it replies at all) to this query, it will be sent to the altered source IP address and not the attacker’s original IP address.
enough talk, show me the code
Visit https://github.com/say4n/dns.amplify to have a look at the source code. The readme and the comments in the codebase should be sufficient to navigate around and play with it.
]]>



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}